예측 모델링을 구축한 후에 모델의 성능을 조금이라도 더 향상하기 위해서는 최적의 하이퍼 파라미터를 찾아 적용하는 방법이 있다. 기존에 내가 해왔던 하이퍼파라미터 방법은 사이킷런의 GridSearchCV 패키지를 활용해 찾는 방법이었다. 하지만, 이는 시간이 조금 오래 걸릴 뿐만 아니라, 하이퍼 파라미터 값을 직접 지정해주어야 한다는 단점이 있다.
Optuna도 물론 값을 지정해주어야 하지만, 조금 더 러프하게 값을 지정해주면, Optuna가 범위내에서 자동탐색을 통해 최적의 하이퍼파라미터를 도출해준다는 점과 시간이 조금 더 빠르다는 점에서 GridSearchCV보다 좋은 것 같다.
import optuna
from optuna import Trial, visualization
from optuna.samplers import TPESampler
from sklearn.metrics import mean_absolute_error
- optuna.trial.Trial.suggest_categorical() : 리스트 범위 내에서 값을 선택한다.
- optuna.trial.Trial.suggest_int() : 범위 내에서 정수형 값을 선택한다.
- optuna.trial.Trial.suggest_float() : 범위 내에서 소수형 값을 선택한다.
- optuna.trial.Trial.suggest_uniform() : 범위 내에서 균일분포 값을 선택한다.
- optuna.trial.Trial.suggest_discrete_uniform() : 범위 내에서 이산 균일분포 값을 선택한다.
- optuna.trial.Trial.suggest_loguniform() : 범위 내에서 로그 함수 값을 선택한다.
XGB과 optuna를 활용한 코드를 살펴보자.
참고 : https://www.kaggle.com/ssooni/xgboost-lgbm-optuna
XGBoost, LGBM + optuna
Explore and run machine learning code with Kaggle Notebooks | Using data from Tabular Playground Series - Jan 2021
www.kaggle.com
# XGB 하이퍼 파라미터들 값 지정
def objectiveXGB(trial: Trial, X, y, test):
param = {
'n_estimators' : trial.suggest_int('n_estimators', 500, 4000),
'max_depth' : trial.suggest_int('max_depth', 8, 16),
'min_child_weight' : trial.suggest_int('min_child_weight', 1, 300),
'gamma' : trial.suggest_int('gamma', 1, 3),
'learning_rate' : 0.01,
'colsample_bytree' : trial.suggest_discrete_uniform('colsample_bytree', 0.5, 1, 0.1),
'nthread' : -1,
# 'tree_method' : 'gpu_hist',
# 'predictor' : 'gpu_predictor',
'lambda' : trial.suggest_loguniform('lambda', 1e-3, 10.0),
'alpha' : trial.suggest_loguniform('alpha', 1e-3, 10.0),
'subsample' : trial.suggest_categorical('subsample', [0.6,0.7,0.8,1.0]),
'random_state' : 1127
}
# 학습 모델 생성
model = XGBRegressor(**param)
xgb_model = model.fit(X, y, verbose=True) # 학습 진행
# 모델 성능 확인
score = mean_absolute_error(xgb_model.predict(X), y)
return score# MAE가 최소가 되는 방향으로 학습을 진행
# TPESampler : Sampler using TPE (Tree-structured Parzen Estimator) algorithm.
study = optuna.create_study(direction='minimize', sampler=TPESampler())
# n_trials 지정해주지 않으면, 무한 반복
study.optimize(lambda trial : objectiveXGB(trial, X, y, X_test), n_trials = 50)
print('Best trial : score {}, \nparams {}'.format(study.best_trial.value, study.best_trial.params))
# Best trial : score 0.3420635047533833, params {'n_estimators': 2592, 'max_depth': 16, 'min_child_weight': 1, 'gamma': 2, 'colsample_bytree': 0.5, 'lambda': 0.0010051916707647715, 'alpha': 9.063895868509052, 'subsample': 1.0}optuna.visualization.plot_param_importances(study) # 파라미터 중요도 확인 그래프
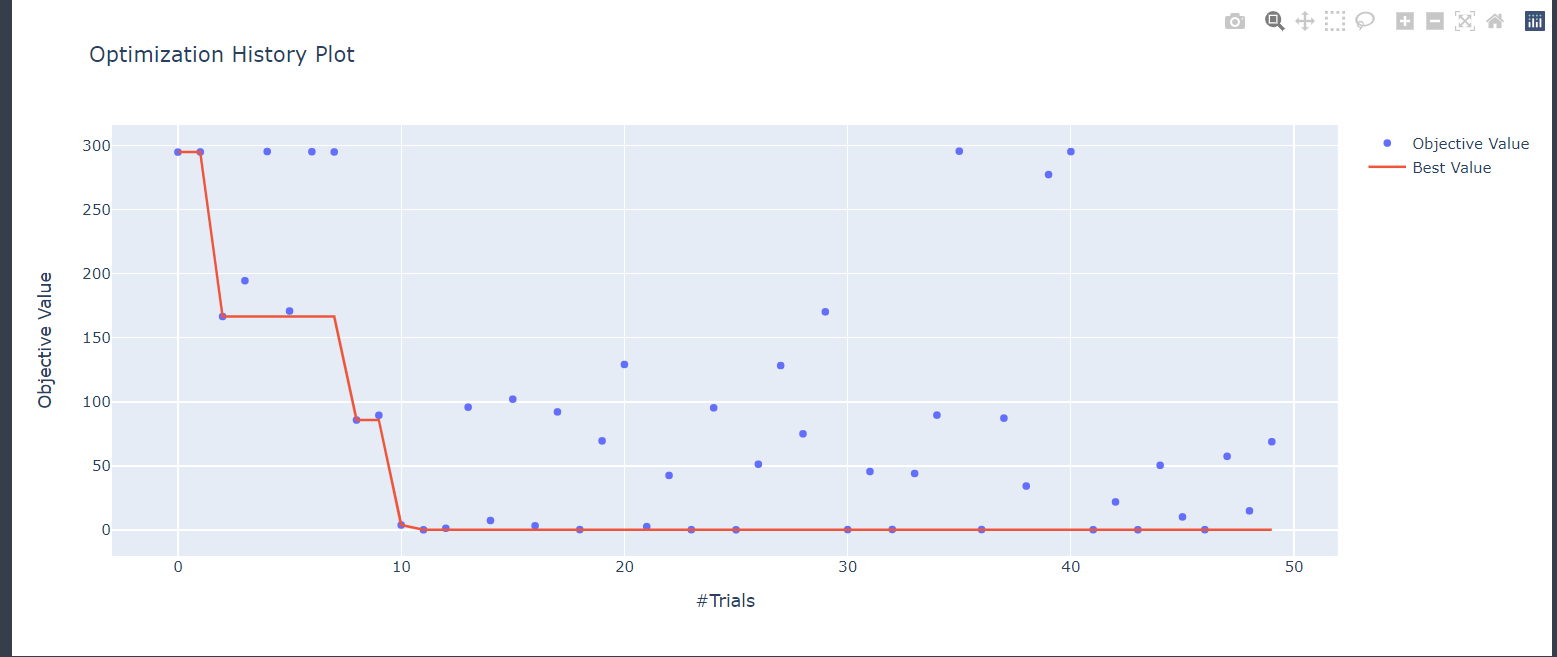
optuna.visualization.plot_optimization_history(study) # 최적화 과정 시각화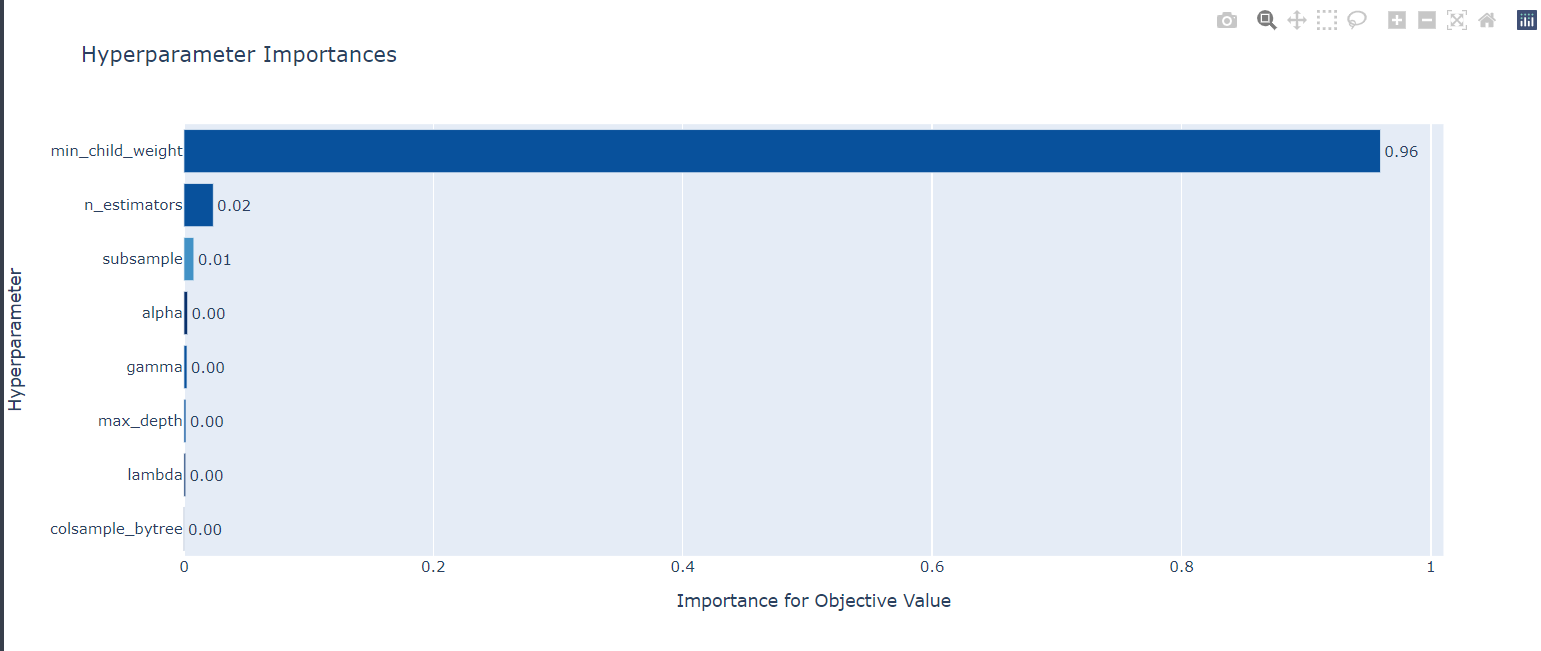
'Algorithm > Python' 카테고리의 다른 글
| [백준 11399번 - ATM] (0) | 2023.01.24 |
|---|---|
| [백준 2720번 - 세탁소 사장 동혁] (0) | 2023.01.24 |
| Plotly 사용법 (0) | 2021.07.05 |
| [Python] Matplotlib 그림의 제목 조절 방법 (0) | 2021.02.03 |
| [Python] Json, Request (2) | 2021.01.14 |

